
Xun Huang (/shuun hwang/)
Email | Google Scholar | Twitter/X | GitHub | Publications | Teaching | Blog
Email | Google Scholar | Twitter/X | GitHub | Publications | Teaching | Blog
I am a Technical Director at Roblox, where I focus on Roblox Reality, the hybrid generative AI architecture powering the next generation of multiplayer photorealistic gaming experiences. Previously, I was the Founder and CEO of Morpheus AI, which was acquired by Roblox. Before that, I held roles as a Research Scientist at Adobe Research, an Adjunct Professor at CMU, and a Research Scientist at NVIDIA.
My work has helped shape the foundations of modern video world models. I pioneered key architectures and algorithms such as Self Forcing and Autoregressive Video Diffusion Transformers (in CausVid). Earlier, I developed one of the first public text-to-image product (GauGAN2), as well as NVIDIA's first text-to-image and text-to-3D foundation models. My research has been cited over 19,000 times, including more than 14,000 from projects that I led.
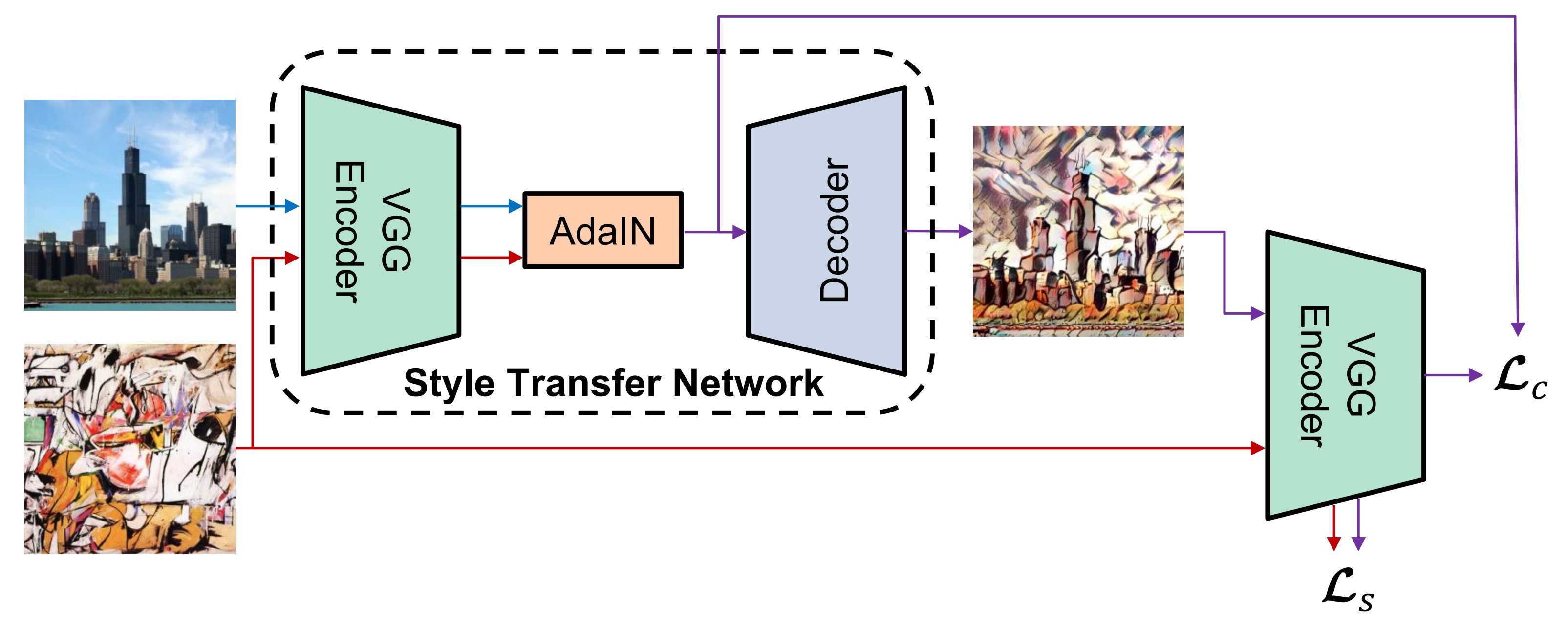
I have been working on multimodal "Generative AI" for 10 years. I obtained my PhD in Computer Science from Cornell in 2020, advised by Professor Serge Belongie. During my PhD, I invented Adaptive Instance Normalization (AdaIN) and was the first to demonstrate its effectiveness in generative neural networks. AdaIN became a foundational component of StyleGAN and played a key role in the first working diffusion model. Variants of AdaIN are now used in nearly all diffusion models. My PhD research was supported by Adobe Research Fellowship (2019), Snap Research Fellowship (2019), and NVIDIA Graduate Fellowship (2018).


CVPR 2026
Xingjian Bai, Guande He, Zhengqi Li, Eli Shechtman, Xun Huang, Zongze Wu
[arXiv]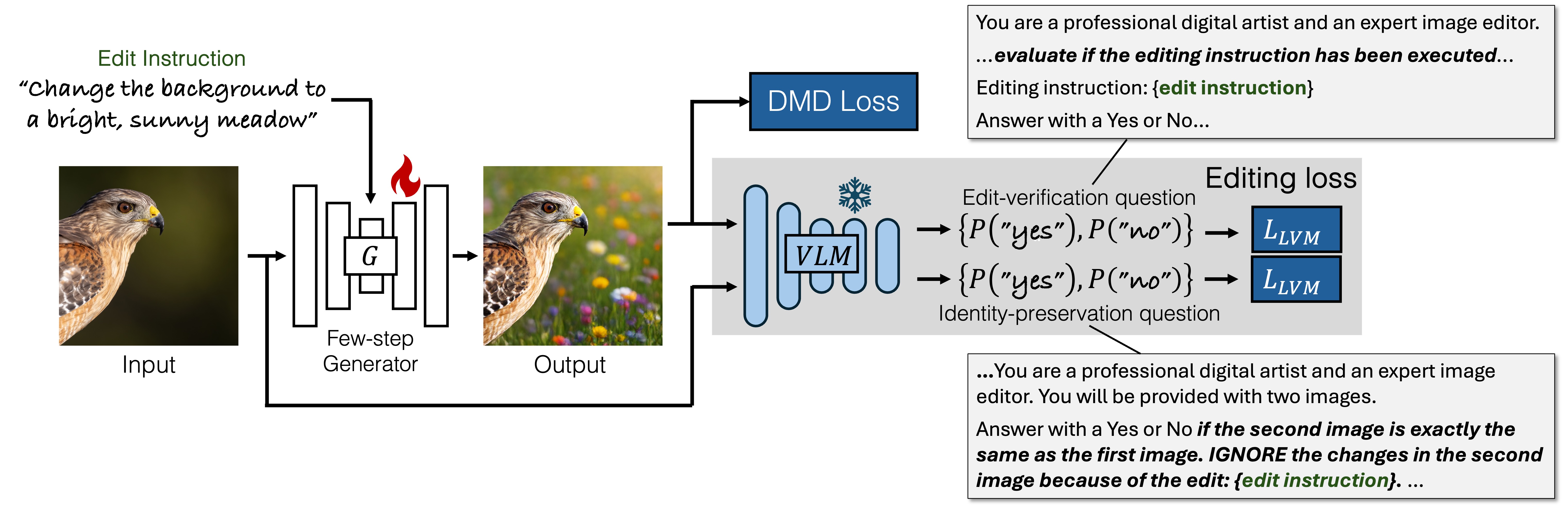



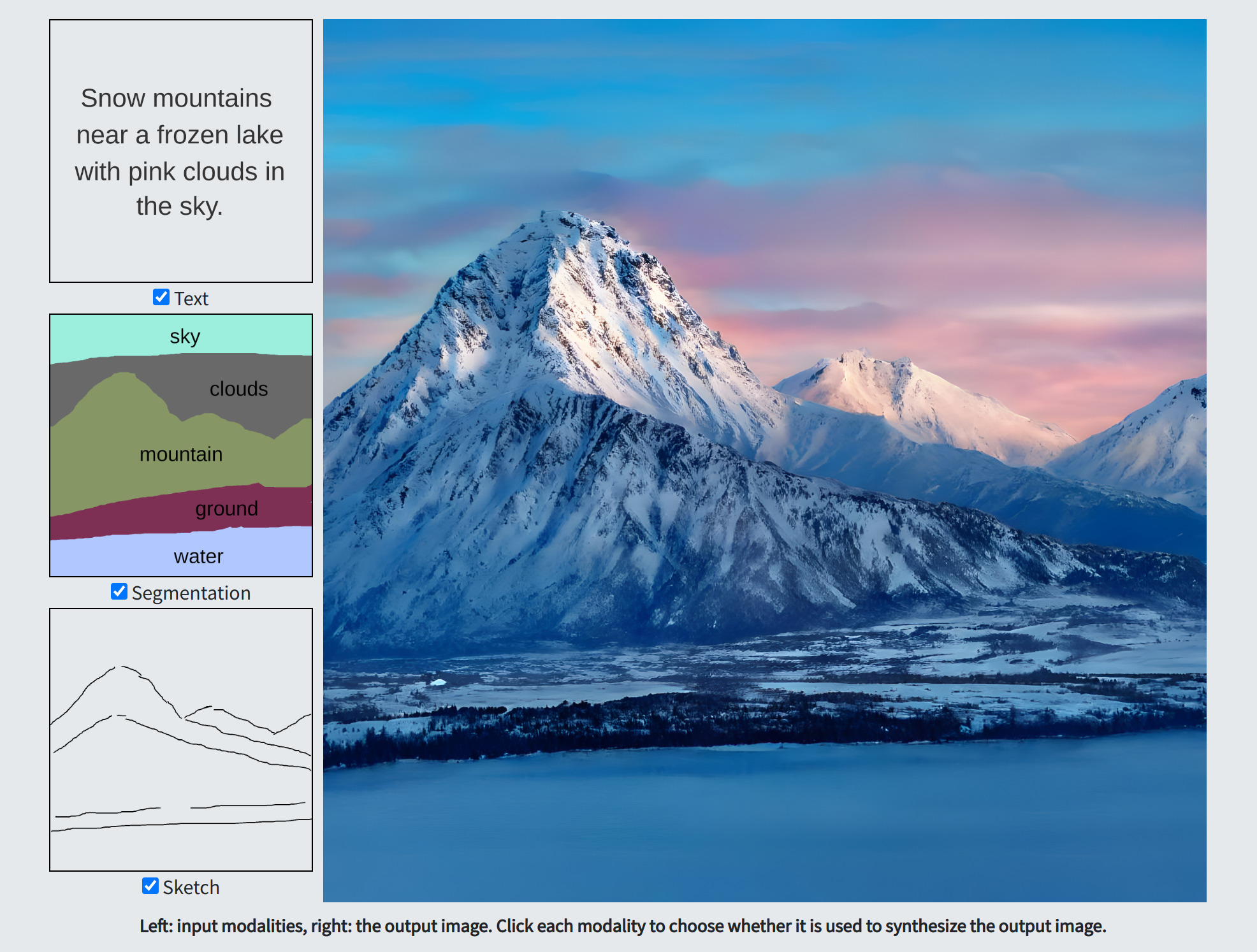
ECCV 2022
Xun Huang, Arun Mallya, Ting-Chun Wang, Ming-Yu Liu
[arXiv] [Project] [Video] [Two Minute Papers]


I have been fortunate to work with many talented students and interns: