Learning to Evaluate Image Captioning
Abstract
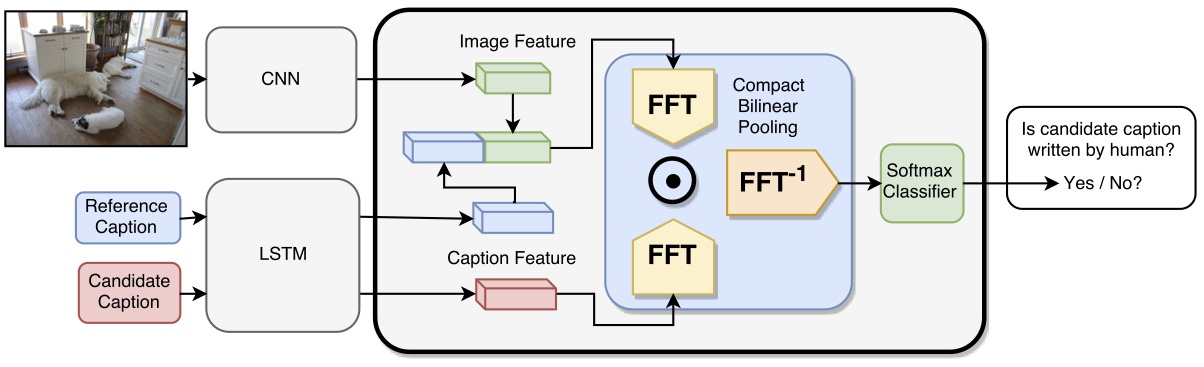
Evaluation metrics for image captioning face two challenges. Firstly, commonly used metrics such as CIDEr, METEOR, ROUGE and BLEU often do not correlate well with human judgments. Secondly, each metric has well known blind spots to pathological caption constructions, and rule-based metrics lack provisions to repair such blind spots once identified. For example, the newly proposed SPICE correlates well with human judgments, but fails to capture the syntactic structure of a sentence. To address these two challenges, we propose a novel learning based discriminative evaluation metric that is directly trained to distinguish between human and machine-generated captions. In addition, we further propose a data augmentation scheme to explicitly incorporate pathological transformations as negative examples during training. The proposed metric is evaluated with three kinds of robustness tests and its correlation with human judgments. Extensive experiments show that the proposed data augmentation scheme not only makes our metric more robust toward several pathological transformations, but also improves its correlation with human judgments. Our metric outperforms other metrics on both caption level human correlation in Flickr 8k and system level human correlation in COCO. The proposed approach could be served as a learning based evaluation metric that is complementary to existing rule-based metrics.